
Claude Code / Codex 国内接入教程(cc-switch)
前言在 AI 大模型的冲击下,我们软件行业现在可谓是发生了翻天覆地的变化,就在上周,零 C++ 基础的我,借助 AI 强大的能力,完成了很多以前想做,但由于技术能力和精力有限而做不到的事,效率、编码质量、甚至全栈能力都得到了极大提高!跟着教程一步一步来,开启你的 AI Agent 快乐编程体验~
什么是 Agent说白了,Agent 就是一个大模型的壳子,我理解的 Agent 主要有以下两种核心特性:
内置了一套 AI 干活的方法论(专业点叫约束条件),可以让大语言模型输出更稳定、成功率更高的回答。
内置了一套脚本,也就是供 AI 调用的工具,借助这些工具,Agent 可以帮你把大语言模型生成的输出,直接转化为落地的成果。说白了就是直接帮你把活干了
只要满足以上两点的,我都认为它是 Agent,但是现代化的 Agent 还有更多好用的特性,比如记忆、MCP 支持、Skills 调用等。
推荐的 Agent市面上的 Agent 工具现在百花齐放,哪些比较好?我们该如何选择呢?就我个人来说,我最推荐这两个 AI Agent 工具——Claude Code 和 Codex,这两可以说是目 ...
UE5+Cesium for UE:02-倾斜摄影加载、地理参考绑定、FlyTo相机飞行
简介在上一篇教程——UE5+Cesium for UE:01-从零搭建可漫游的“真实地球”,10分钟让你的角色跑遍全球!中,我们学习了
UE中如何使用Cesium for Unreal添加全球地形、卫星影像、建筑白膜以及光照,以及怎样设置初始经纬度作为UE场景的原点
如何添加第三人称角色、Dynamic Pawn进行游玩探索
这一期,我们将学习如何使用Cesium地理参考组件
实战演练1.Cesium Globe Anchor这是一个Cesium for Unreal插件提供的组件,用于将UE原生的Actor固定到Cesium创建的地球坐标系中。在UE场景中,拖入一个任意的Actor,比如一个圆锥,此时改变Cesium Georeference的经纬度参数,可以看到地球转到,但圆锥固定在原地不会跟随地球转动。
选中圆锥Actor,在细节面板中,改变其可移动性为可移动,并为其添加一个Cesium Globe Anchor组件。此时再次改变Cesium Georeference的经纬度参数,可以观察到圆锥体固定在了地球 上,会随着地球上的物体一起移动。并且选中Cesium Globe ...

UE5+Cesium for UE:01-从零搭建可漫游的“真实地球”,10分钟让你的角色跑遍全球!
简介在UE智慧大屏项目开发中,Cesium for Unreal插件是非常便捷的选择,它提供了全球的地形及卫星影像、建筑白膜以及基础的地理参考等,只需要注册一个免费的Cesium ion Token即可一键将需要的资产添加到UE项目中。
UE项目实战1.启用插件创建一个UE项目,在插件中搜索Cesium for Unreal启动,重启后即可使用插件。
2.添加资产点击connect to Cesium ion,网页登录授权后,点击+号添加Cesium SunSky(包括太阳、太空盒、大气、雾效等)、Cesium World Terrain + Bing Maps Aerial(全球地形及卫星影像)、Cesium OSM Buildings(建筑白膜),等待资源加载完成,即可看到像图中一样的画面。
3.设置初始位置进行项目开发时,往往需要我们在某个固定的经纬度附近进行场景搭建,这时,我们需要控制相机飞到指定位置。如果直接控制视口相机飞行,这将十分困难。此时,我们需要点击大纲中的Cesium Georeference,在细节面板中,设置UE场景的原点经纬度高程参数——下图中的Origin ...

SSL证书自动续期并同步到腾讯云cdn(阿里云宝塔版)
问题背景:最近我休婚假期间,从朋友那得知网站https访问出问题了,简单看了下发现是ssl证书过期了。免费的ssl证书现在的有限期是90天,每三个月就得续签一次。三个月前我从腾讯云服务器迁移到了阿里云服务器,并用上了宝塔面板,开启了网站的ssl证书自动续期。但由于我的网站使用了cdn加速服务,还需要将ssl证书上传到腾讯云服务器才能实现完全自动化,当时迁移时太忙手动处理了下,想着后面再说结果给忘了。
实现思路:询问了AI,AI说宝塔其实是可以支持自动同步到腾讯云cdn的,但我看了下我的阿里云版的宝塔面板,里面确实没有这个功能(坑!)。因为这个重新装一遍系统也不太现实(太麻烦),于是我决定使用AI写一个linux定时任务来实现ssl证书上传到腾讯云并绑定云资源的需求。
实现步骤:一、服务器SSL证书免费申请及自动续期这一部分非常简单,宝塔做好的功能,点点点就可以实现了,具体步骤如下:
在宝塔面板左侧点开网站模块,点击要配置的网站,点击SSL模块配置,选择Lets Encrypt,点击申请证书,根据提示操作即可
二、服务器SSL证书同步到腾讯云CDN并配置域名绑定1.编写脚本查询了腾讯云 ...

保姆级教程!手把手教你把DEM数据变成Cesium地形切片
前言在 WebGIS 开发领域,Cesium 凭借其强大的开源生态,已成为三维GIS可视化引擎的首选。构建高质量的三维应用离不开高精度的地形数据支撑。在常规的外网开发、个人学习中,我们通常的做法是注册一个 Cesium Ion 账号,创建 token,最后通过 token 来调用 Cesium Ion 提供的全球地形,确实方便快捷。
然而,在内网涉密环境或商业化私有部署场景下,受限于网络隔离、数据隐私及授权合规性等因素,依赖在线 Token 的方案已经不再适用。这时就需要我们自己来构建一套三维地形切片服务。本文将详细记录在 Windows 环境下,从 DEM 数据处理到最终生成地形瓦片的完整工作流。通过本教程,你将掌握低成本搭建离线地形服务的核心技能。
工具准备下面是我们需要用到的工具列表:
QGIS - 开源GIS数据处理工具
OpenTopography DEM Downloader - QGIS插件,用于下载DEM数据
Docker Desktop - 用于给ctb-quantized-mesh提供运行环境
tumgis/ctb-quantized-mesh - 著 ...
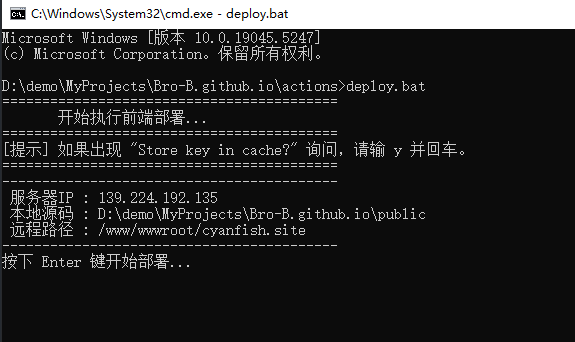
55-前端项目自动部署bat脚本分享
背景之前为了学习windows的bat脚本,我在AI的帮助下写了一个将前端包上传到服务器的部署脚本,使用起来还算方便,相比于 GitHub Actions 在代码推送时强制触发的自动化流程,我这套“半自动”方案可以自由控制什么时候发新版本,具有更高的灵活性。
由于最近在脚本中集成了刷新cdn的js脚本,考虑到前端开发者的技术栈偏好与代码的可维护性,于是想着把整套部署流程全部用nodejs脚本实现,毕竟作为一个前端开发者,js是我更熟悉的语言,具有更好的可读性。本文的目的只是在这里将现有的bat脚本存个档,或许它在未来的某一天会发挥它的价值也说不定。
代码deploy.bat123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106 ...
开源工具推荐 | Cesium 交互编辑神器来了!像专业建模软件一样操作 3D 模型
导语相信很多做 WebGIS 开发的同学,都遇到过类似的需求:
公司做gis平台,需要实现模型的交互式编辑功能,在网上找开源项目,或费劲自己封装一套工具,结果发现要么工具简陋,bug满天飞,坐标错乱;要么交互体验不理想,不能满足要求。
在 Unity、Blender 或者是 Three.js 编辑器里,我们习惯了用Gizmo(变换控制器) 来随心所欲地操作物体。但在 Cesium 的开源生态里,一直缺乏一个轻量、高性能且开箱即用的同类型工具。
UE5引擎中的变换工具
今天,给大家推荐一款开源神器:cesium-transform-gizmo。它可能就是你一直在寻找的那块拼图。
🚀 什么是 cesium-transform-gizmo?cesium-transform-gizmo 是一款专为 CesiumJS 打造的高性能、交互式模型变换控制器。
它完全使用 TypeScript 编写,为你的 Cesium 应用提供类似于 3D 建模软件的操作体验。无论是 Model (gltf/glb) 还是 3D Tileset,都可以通过它进行丝滑的平移、旋转 ...

告别 Copilot 付费!谷歌 Gemini CLI 每天白嫖 1000 次请求,保姆级教程来了
💡 背景与痛点之前写项目时,体验了Github Copilot Agent模式的强大功能,它能直接在执行任务时,自动读取项目里关联的上下文。然而我注册了账号,领取免费试用,高高兴兴爽了一个月后,试用到期了。
本着“能白嫖绝不付费,免费就是最好的”原则,我挖掘到了 Gemini CLI 这款神器。它不仅拥有强大的代码辅助能力,更重要的是:它每天提供 1000 次免费请求额度,量大管饱!
于是我在网上各种找攻略,找教程,翻官方文档,踩遍了各种坑(尤其是账号和网络配置),终于总结出了这套10分钟极速上手指南。希望能帮你节省时间,直接享受 AI 编程的快乐。
🛠️ 先决条件在开始之前,请确保你的环境满足以下要求:
Node.js:版本需 > 20
操作系统:支持 macOS、Linux 或 Windows
Google 账号:必须使用个人账号(划重点:学生账号、组织账号无法享受 1000 次/天的免费额度,详见后文避坑指南)
🚀 实战步骤:手把手教你配置1.安装 Gemini CLI打开终端(CMD或 PowerShell),运行以下命令进行全局安装:
1npm ...

从 0 到 1 手写 WebGL:原来 3D 渲染的底层逻辑,就是拍照片
引言:知其然,更要知其所以然作为一个长期与 Cesium 打交道的 Giser,在搭建Web3D场景时,面对Shader、矩阵变换、酷炫材质等深层定制需求,我常常因不了解三维渲染底层逻辑而感到困惑与束手无策。为此,我在B站上学习了闫令琪大佬的计算机图形学课程,并使用原生WebGL在实践中验证理论。
这篇文章不讲复杂的 API 调用,只讲最纯粹的渲染逻辑。让我们从零开始,写出属于 Web3D 的“Hello World”,一起攻克那些让人头秃的图形学概念!
建立基本概念在正式开始写代码之前,我们首先需要对以下几个概念建立起明确的认知:
1.WebGL到底是什么?很多人说到 WebGL ,就想到三维、想到酷炫的3D动画效果,认为它是一个无所不能的3D渲染引擎。但实际上WebGLFundamentals 在教程中给出了清晰的定义:
WebGL仅仅是一个光栅化引擎,它可以根据你的代码绘制出点,线和三角形。 想要利用WebGL完成更复杂任务,取决于你能否提供合适的代码,组合使用点,线和三角形代替实现。
换言之,WebGL实际上只负责在2D的画布上,画点、线、三角形,以及上色而已,它的功能相当 ...
Hexo 进阶实战:利用 Hook 机制实现 hexo new 自动注入永久链接
背景使用hexo框架写文章时,需要为文章生成永久链接,以保证即使文章的文件名更改后,文章的链接也不会变化。之前我使用了hexo-abbrlink插件来完成这一工作,但其存在一个问题——当我没有在本地没有使用hexo generate或者hexo server命令时,文章的abbrlink不会生成,此时我提交代码到github上,触发CI/CD流程,文章的abbrlink不会被记录到远程仓库中。
思路文章的abbrlink应该在hexo new命令执行时生成!查看hexo官网API文档,发现可以监听new事件,于是想到可以在事件的回调中,为文件添加上abbrlink属性
解决在根目录下新建一个script目录 ,创建一个文件:auto-abbrlink.js,将下面的代码粘贴进去:
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657const fs = require("fs")const path ...
ElementUI 样式死活改不掉?这 2 招专治各种不服!
背景:在前端开发中,UI 设计师的需求往往与 ElementUI、Ant Design 等第三方组件库的默认样式存在冲突。为了还原设计稿,我们经常需要对组件样式进行“魔改”。 很多新手在修改样式时,常遇到样式不生效或造成全局污染的问题。本文总结了在 Vue 项目中定制第三方 UI 样式的几种最佳实践,帮助大家优雅地解决由 scoped 带来的样式隔离难题。
方法总结:方案一:全局样式覆盖(Global Override)适用场景: 需要修改整个项目中某类组件的通用样式(如:统一修改所有按钮的圆角、统一 Input 输入框的高度)。
实现方式: 在项目样式目录下新建一个专门的重置文件(例如 styles/element-reset.scss),编写覆盖代码后,在入口文件引入。
创建重置文件 src/styles/element-reset.scss:
12345678/* 覆盖 element 全局样式 */ .el-button { border-radius: 2px; /* 比如将圆角改小 */ } /* 修改所有弹窗的头部背景 ...
前端视频流终极方案:Vue3 实现 RTSP 毫秒级低延迟播放 🔥
📝 背景在视频监控、直播等场景中,RTSP (Real Time Streaming Protocol) 是一种广泛使用的视频流传输协议。然而,痛点在于:**浏览器原生并不支持 RTSP 协议 **,传统的 <video> 标签无法直接播放 RTSP 流。
为了在 Web 前端实现 RTSP 视频播放,我们需要“曲线救国”:将 RTSP 流转换为浏览器原生支持的 WebRTC 协议。
本文将手把手教你如何使用 MediaMTX 作为流媒体服务器,在 Vue3 前端项目中实现丝滑的 RTSP 视频流播放。
🛠️ 解决方案我们需要两个核心工具:
MediaMTX: 一个轻量级的开源流媒体服务器,核心能力是支持 RTSP 转 WebRTC。
FFmpeg: 强大的音视频处理瑞士军刀,用于模拟 RTSP 视频流进行开发测试。
技术架构图:
1RTSP源流 --> MediaMTX服务器 --> WebRTC协议 --> 浏览器播放
💻 实操演练1. 视频流模拟首先,下载并启动 MediaMTX。
然后,下载 FFmpeg 工具,在FFmpe ...